Update:
Comparision between openMVG-openMVS pipeline and Meshroom :
So far, openMVG and openMVS have given more than satisfactory results, providing a good 3D reconstruction with low quality images. However a major issue with these libraries was the high amount of time(~1hr on 10-20 images) taken for the final dense cloud generation.
Both libraries utilize the CPU for reconstruction, whereas the process could potentially be accelerated through the use of a dedicated GPU. However, openMVG currently doesn’t support CUDA, and openMVS doesn’t fully utilize CUDA(it only uses CUDA computing for refining the final textures).
We decided to test another open source library, Meshroom. It’s MVS portion uses CUDA, and was expected to provide quicker results.
Another benefit to using Meshroom was that it provides pre-compiled binaries, in contrast to openMVG-openMVS which need to be built from source before they can be used. This allows Meshroom to be setup a lot quicker.
Since it requires a higher amount of resources than our laptops provide, we turned to Googles free cloud service, Colab, which provides a linux instance with the following specs :
GPU : 1xTesla K80, 2496 CUDA cores , 12GB GDDR5 VRAM
CPU : Intel Xeon @ 2.30GHz(1 core, 2 threads)
RAM : ~12.7 GB
Storage : ~33 GB
Meshroom was tested on 2 datsets, a test dataset provided them and on our Rubiks cube photos.
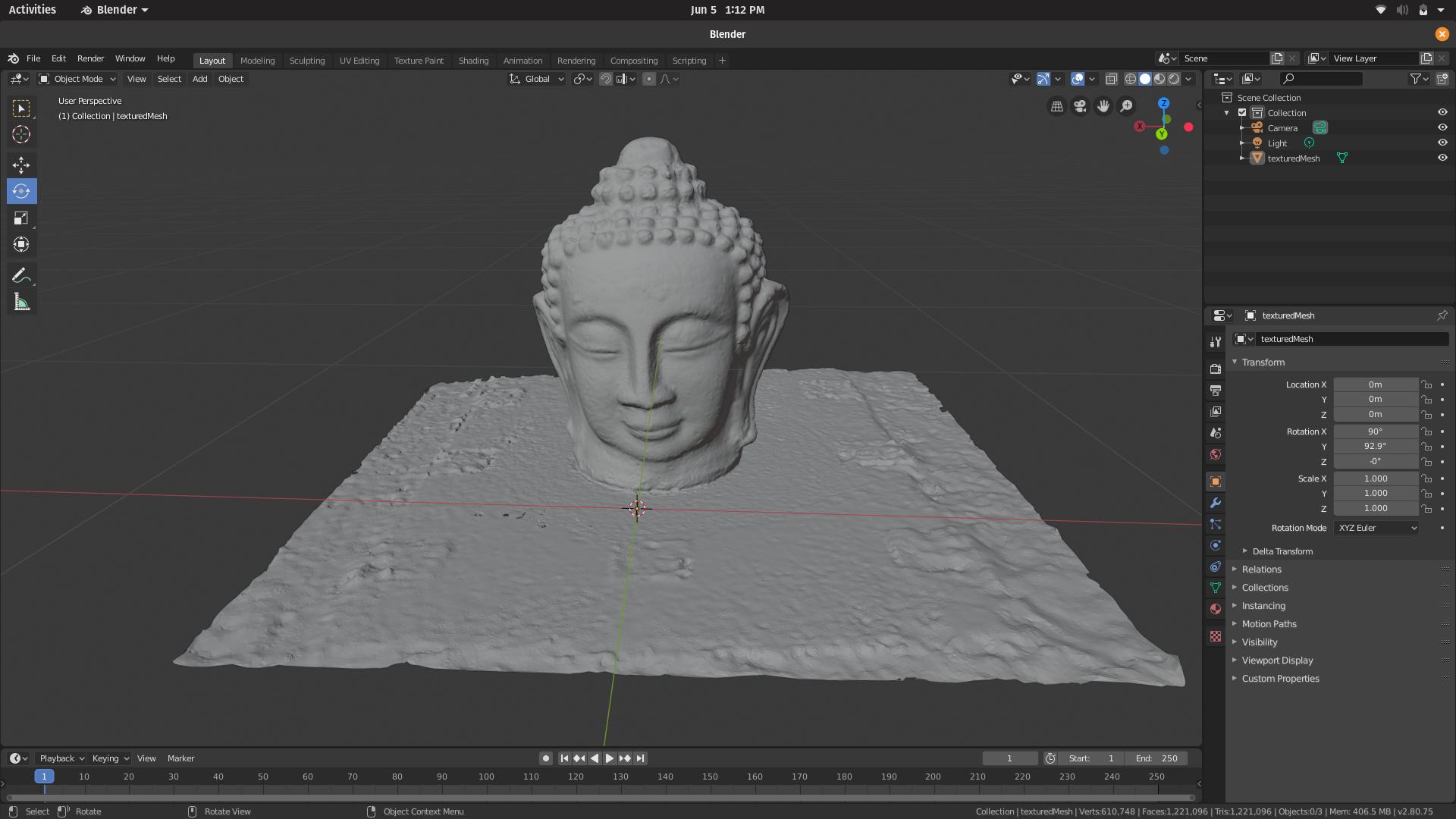
Buddha Dataset(67 High Res Images, total time for final Texture generation was about an hr) :
Rubiks Cube dataset(13 low Res Images, ~10 minutes for final texture generation) :
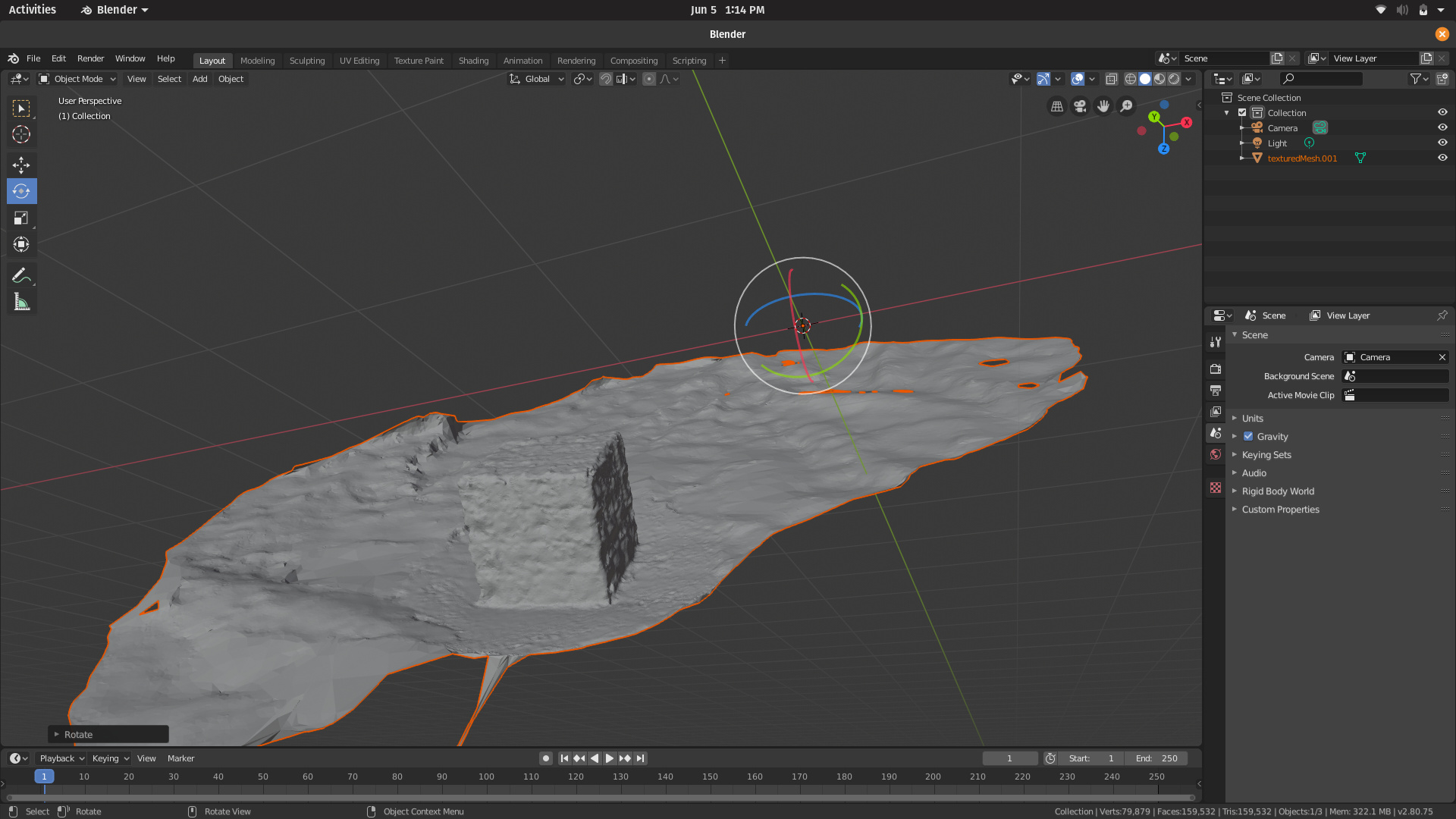
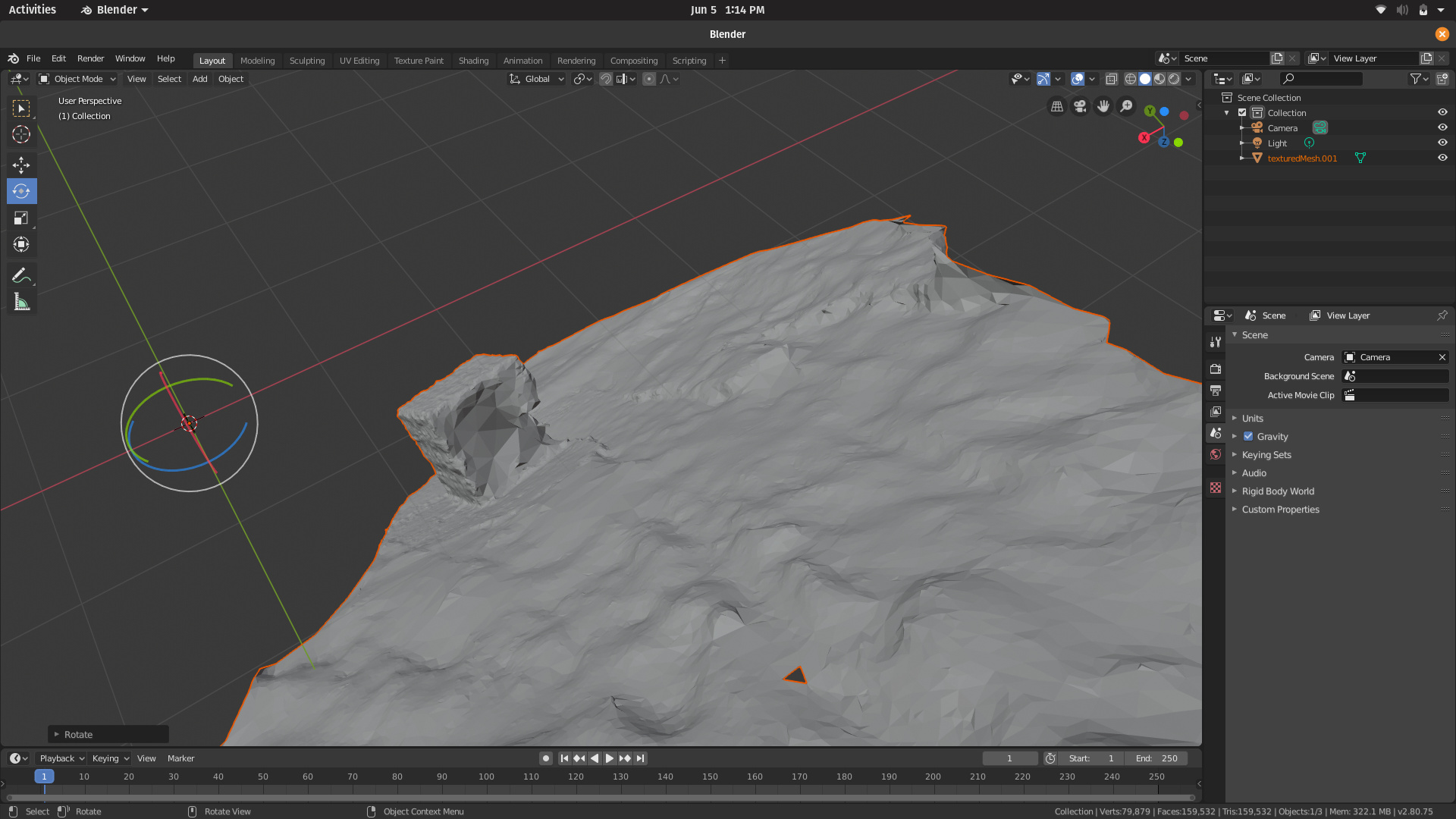
Though Meshroom generated the final texture for the Rubiks cube almost 6 times quicker, the output was lacking and even broken in some areas. The Buddha dataset took over 2 hours on openMVG-openMVS, however the output could not be viewed as it was highly detailed and required more RAM than our laptops could provide.
So Meshroom, as compared to openMVG-openMVS, doesn’t work well with low resolution images, and requires a lot of images.
Hence we plan to not use Meshroom for the final output, instead we plan to use it as an intermediary step while testing to visualise how the output might look, and to know which faces require additional images for proper 3D generation.